Hey! Yes, this is 3rd post on this forum about the same thing, but before you go and click away, hear me out, maybe you could help me, I would really appreciate that!
So, what’s the problem, I hear you ask… well, it’s kind of simple and complicated at the same time!
Simply put, flight time! Yeah, it’s great on most drones, but mine is an exception I guess! 7 minutes on a fully charged 2300 mah 3s battery… Yeah, not great, absolutely not!
Now, don’t tell me to rebuild my drone, I already did that, it flies 2 minutes more (the previous flight time was around 5 minutes) but still, believe me, not great!
But then I see these “amazing and expensive” drones like the phantom, autel evo 2, mavic, parrot, and all of the others there are, they (mostly) fly more than 7 minutes, and after having experience with 2 drones other than mine, I can surely say: Yes, my drone flies great (by the most part) and takes amazing videos but what restricts that is the flight time, FOR SURE!
So, do you have an answer for me? Maybe 4s battery? More capacity battery?
And before you tell me this, no, I can’t reduce the weight of my drone because everything I have attached is used and needed! So please find other ways! I am sure you have something in mind, right?
Also, thank you to everyone who helped me in the past to make this drone and set up it! Now it flies now just the finishing touches are left, this is one of them!
Thanks again,
Yaros
Edit:
Here I add some pictures of my drone if needed!
Hi, I think it’s AMAZING that you can hover more than 3 minutes with that 20kg drone, with 29x7 props, 200KV motors on that 2.3Ah 3S PACK
I hope you see the issue here, your post contain nothing useful that can give a meaningful clue.
In general: for good efficiency, you need to balance the motor RPM and power with KV and propeller pitch/size and battery voltage.
Also, using lower current, will allow to spend more energy before the cell voltage drops off at the end, so you would usually like to operate at low current (higher voltage, rather then higher current)
Let’s link to one of the other long winded posts about this same topic so people that haven’t had the good fortune to suffer thru it can can be entertained now.
I’m proud to say that someone even posted “don’t listen to anything dkemxr says”. Like I said entertaining!!
Yes, that’s my other post. But we are returning to the same thing, not good.
Now, I have some questions
First of all, will a slightly heavier 3000 mah battery give it more flight time?
And also, are there other options, not replacing motors?
Sorry, but this is not a 20 kg drone, it weights 1.5kg, the props are from DJI Phantom 3, I think 9,5x4,5 or similar. The motors are 920kv!
You don’t think it could work?
IT’S NOT entertaining for me. If it is to you then feel free to leave this discussion, will not even argue with you!
I am searching solutions and you only are making it worse… Doesn’t work like that here!
For something I mentioned that it’s the 3rd time I’m posting same thing, no solution, well, gonna keep posting because I want to find a solution, even if you don’t have one, maybe someone has one! So if you don’t have and don’t want to “suffer” as you said, then feel free to ignore this topic!
This is a forum where people can ask questions and don’t need to be insulted by others! So I’m doing just that! Trying to find a solution!
Thank you for your help in the past, but if you don’t think it’s worth the effort, to solve this problem, then as I said, feel free to leave the discussion!
Thanks!
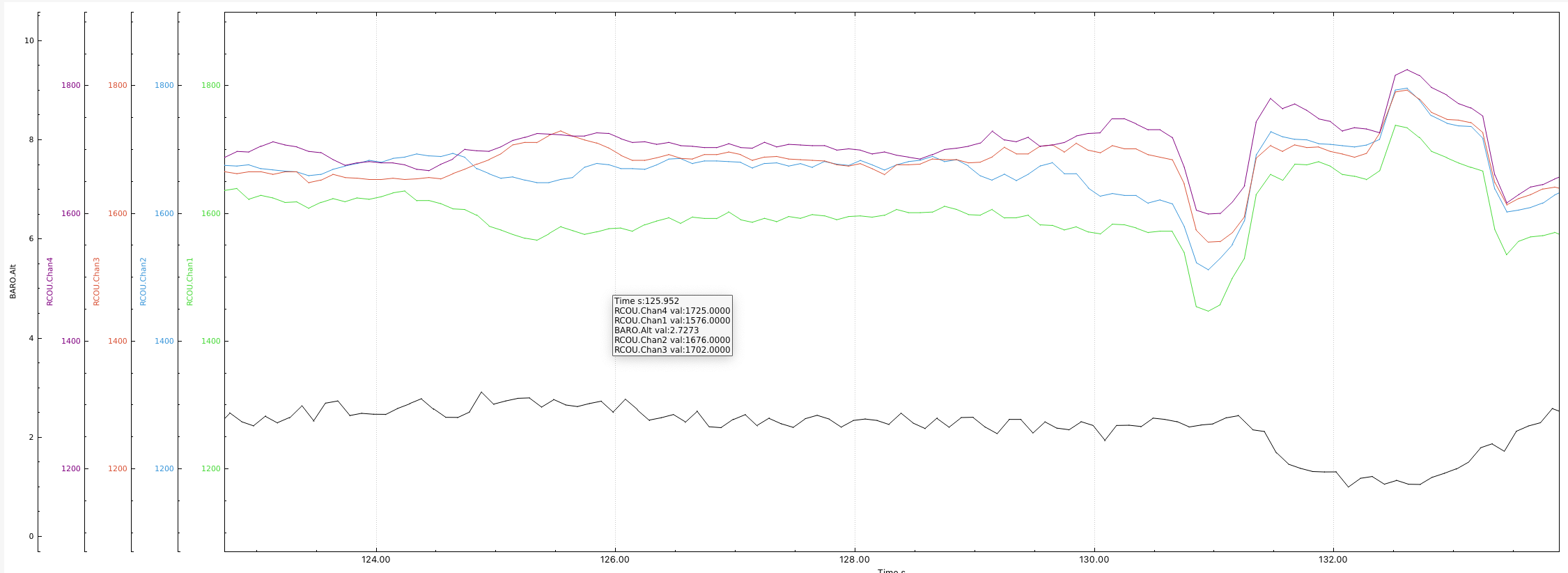
OK, I’ll try to be helpful. There isn’t a lot of log content from AC 3.2.1 and you don’t have Voltage or Current logging. With what is available it shows an average commanded motor output of ~1650µs at Hover (THo ~650). So regardless of flight time desired this configuration has insufficient thrust/weight.
If you switched to 4S power and determined a battery capacity/weight that wouldn’t put you back to where you are now perhaps you could achieve a bit more flying time. For a significant increase you would need lower kV motors and larger props.
Some may suggest looking into Li-Ion power and for some use cases it can increase flight time significantly. But it’s a finer balance of available current/weight and unless you build your own pack they can be expensive. I fly a 5" quad with the same 3500mah pack I use in a plane and the flight time is impressive. But it’s light and no speed demon.
Yes, I will look into 4S power, but also Li-Ion packs can’t deliver much current, so they work good for small quads, but not very good for large and heavy ones!
If you know a battery that might work, then send links! Thank you!
As @dkemxr points out, you are not logging V or I and the discussion is about flight time, not much use.
You seem to be pushing the quad around the sky in those logs, not much help.
1: enable V and I logging
2: Do a hover flight in still air for as long as you can, to battery FS would help
3: post log here for review
As @dkemxr also points out, your motor out is indicative of overweight/underpowered out of balance flight. Do the above so we can see what is going on.
My Power Module recently went in flames… so no luck there! Maybe will buy replacement soon!
Also I will do a steady hover in the air some day soon!
I was pushing the copter in the air to test the new PID values!
Use a 4s battery then report back with a log. Something around a 4s 4Ah is probably your best bet. I made a similar recommendation in your last posts.
Also this forum is dedicated to ArduPilot help. We all are glad to help around with general multirotor knowledge - but please don’t spam with several posts about the same thing. It’s like asking for help about fixing your computer hardware on a Windows forum.
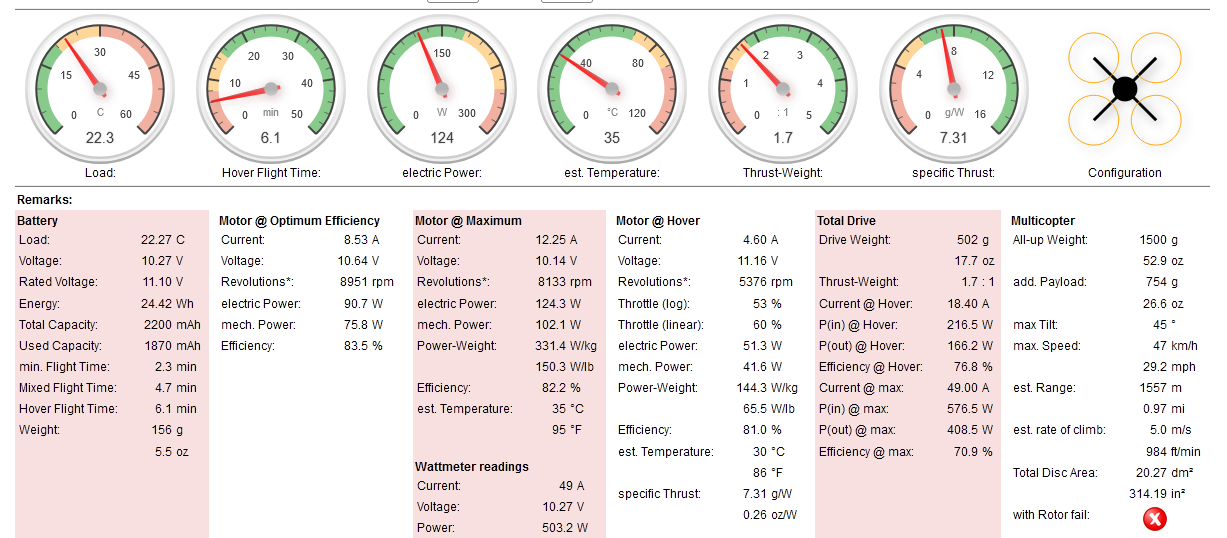
You are actually doing well with what you have. According to ecalc you would get less flight time than what you are experiencing - it’s a bit conservative like that.
I think that just changing to 4 cell will over heat those motors.
It’s very tough with that sized frame and weight, you are right at maximums - generally you need more powerful motors, bigger props and a correspondingly bigger battery.
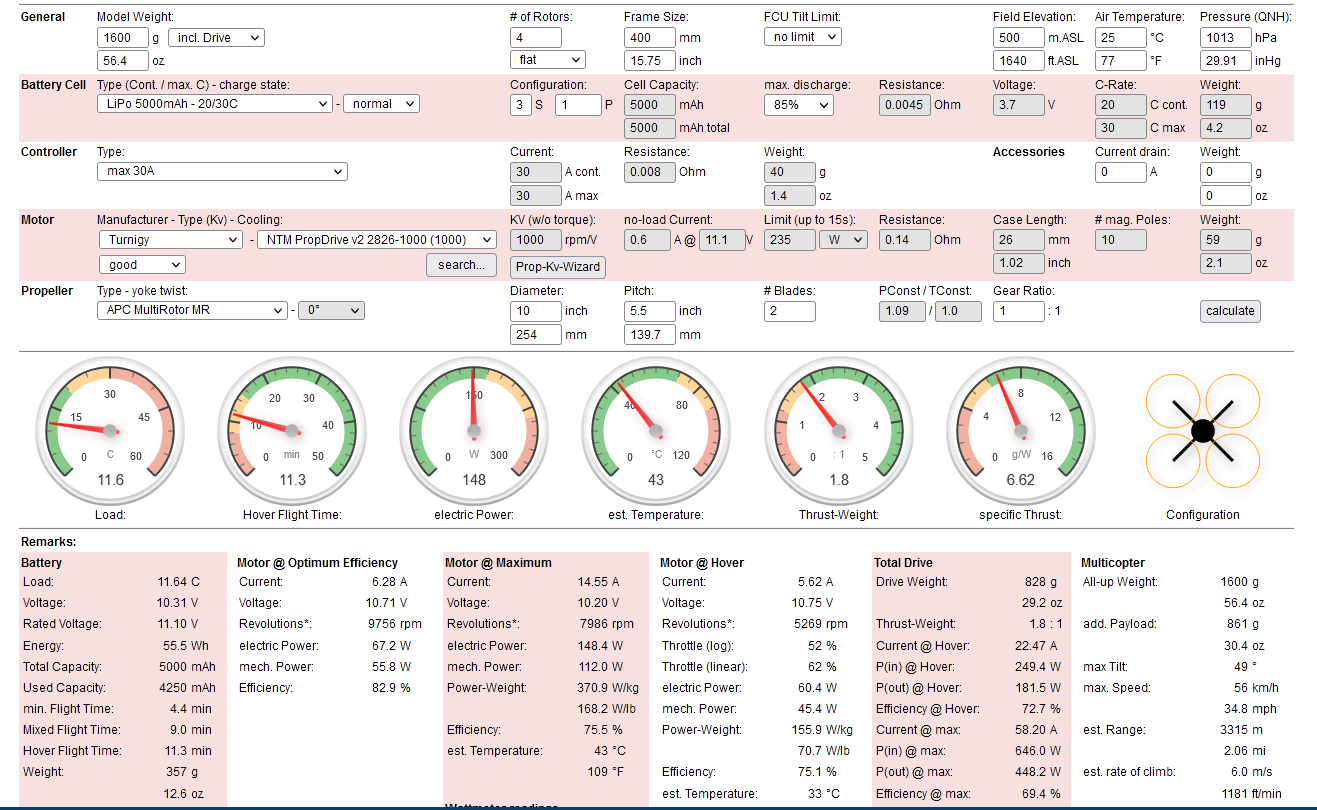
Something like this could work, and trust me, I spent some time looking for a combination that was better than what you have now: 5Ahr 3 cell, NTM Propdrive 2826 1000kv, APC MR 10x5.5, and dont substitute cheap copies. I increased the total weight a bit to allow for heavier battery and motors.
The next step is going to a bigger frame so you can fit about 12 inch props, or get an ecalc subscription and spend about a week finding what works and what’s actually available for purchase.
I’ve actually used a similar combination to my recommendations so it should work if you can source the parts. The f450 frame will be your next issue, and then you’ll want a new flight controller for better tuning and more features.
 now just the finishing touches are left, this is one of them!
now just the finishing touches are left, this is one of them!