Copter-4.0.3-rc1 has been released for beta testing and can be downloaded using Mission Planner, QGC or can be directly downloaded from firmware.ardupilot.org.
Changes from 4.0.2
Bug Fixes:
a) “RCInput: decoding” message watchdog reset when using MAVLink signing (Critical Fix)
b) HeliQuad yaw control fix
c) Do-Set-Servo commands can affect sprayer, gripper outputs
d) BLHeli passthrough fix for H7 boards (CubeOrange, Holybro Durandal)
USB IDs updated for “composite” devices (fixes GCS<->autopilot connection issues for boards which present 2 USB ports)
RCOut banner helps confirm correct setup for pwm, oneshot, dshot
ZigZag mode supports arming, takeoff and landing
The most important fix is the first one which can lead to the autopilot rebooting (via the watchdog) at the moment the RC transmitter is first turned if MAVLink2 signing is enabled. The issue involves memory corruption when “RCInput: decoding xxx” is sent to the ground station. We are so far not aware of any crashes caused by this issue.
I’ve put a few names below that can hopefully help with some of the testing but I’ve probably missed a few names and all feedback is very welcome!
1c) @ulfbogdawa, can you confirm the do-set-servo works with the sprayer?
1d) @vosair, @keilie, can you confirm BLHeli passthrough is working on the CubeOrange?
2) @smartdave, maybe you’re in the best position to confirm the CUAV v5+ connection is working OK now?
4) @JacksonUAS, maybe you could give ZigZag a test?
@rmackay9 sorry, I cannot confirm that BLHeli passthrough works with the CubeOrange
BLHeliSuite32 connects to the CubeOrange but the ESC settings are not loaded.
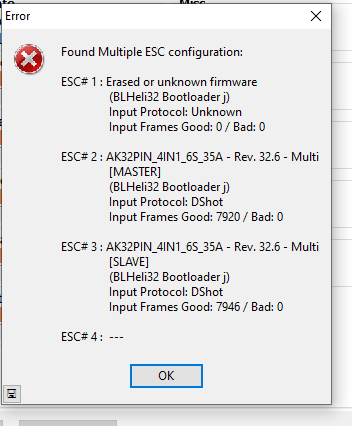
@rmackay9 Passthrough still does not work for me. I think 4.0.2 might have bricked ESC 4 on this AK32PIN? This is the error message I get when I try to connect -
This was a known good ESC that had only performed motor tests and hasn’t ever been flown.
OK, well, thanks for testing anyway. Let’s move the discussion back to the original thread here because I suspect it’s going to continue to be very detailed.
Sorry, I just have to add I am having the same issue, PixRacer T-Motor 35A
Only difference is, if I keep poking and checking both parameters and BLHeliSuite32 settings, they will appear.
I thought it suspicious that the right motor behaved and spin and the left doesn’t.
All tested and checked.
During trying various settings I was able to get the front left running but it also twitched when disarmed, then it ran and I thought I might have solution.
Next morning back to square one, right only.
Thats enough clutter, sorry, but seeing that same thing happening I had to add.
Thanks for the report. It seems that BLHeli is still difficult to setup and get working correctly and my guess is that this is because of multiple software issues (on BLHeli side and/or in AP) and because the connection and configuration is complex and perhaps not adequately documented.
Because there are likely multiple different causes of problems could you create a new topic in this Copter-4.0 category and then we can narrow down where things are going wrong with your setup?
If you can include a log file so we can get the parameters and also see the “RCOut:” message that would be great.
Hello.
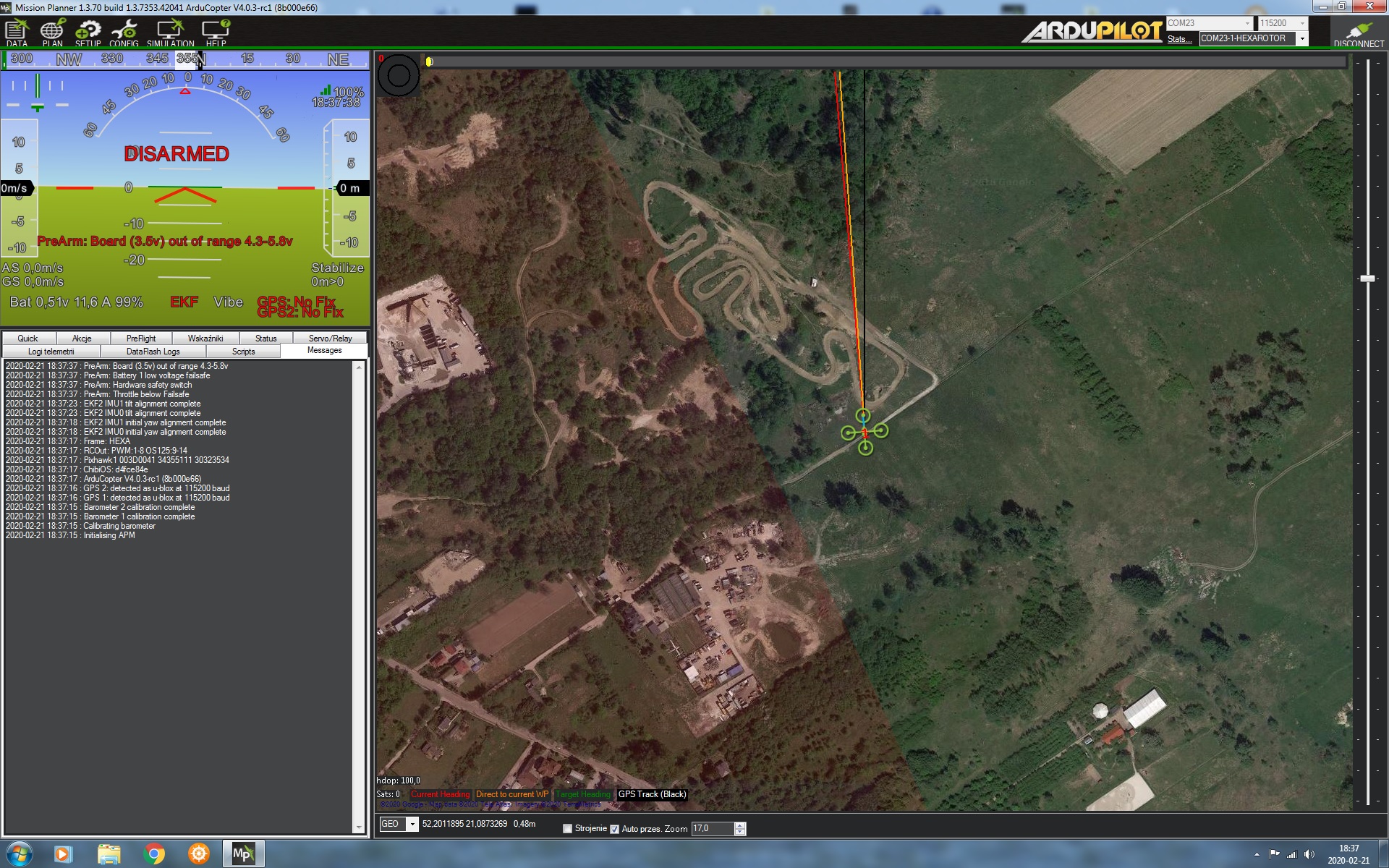
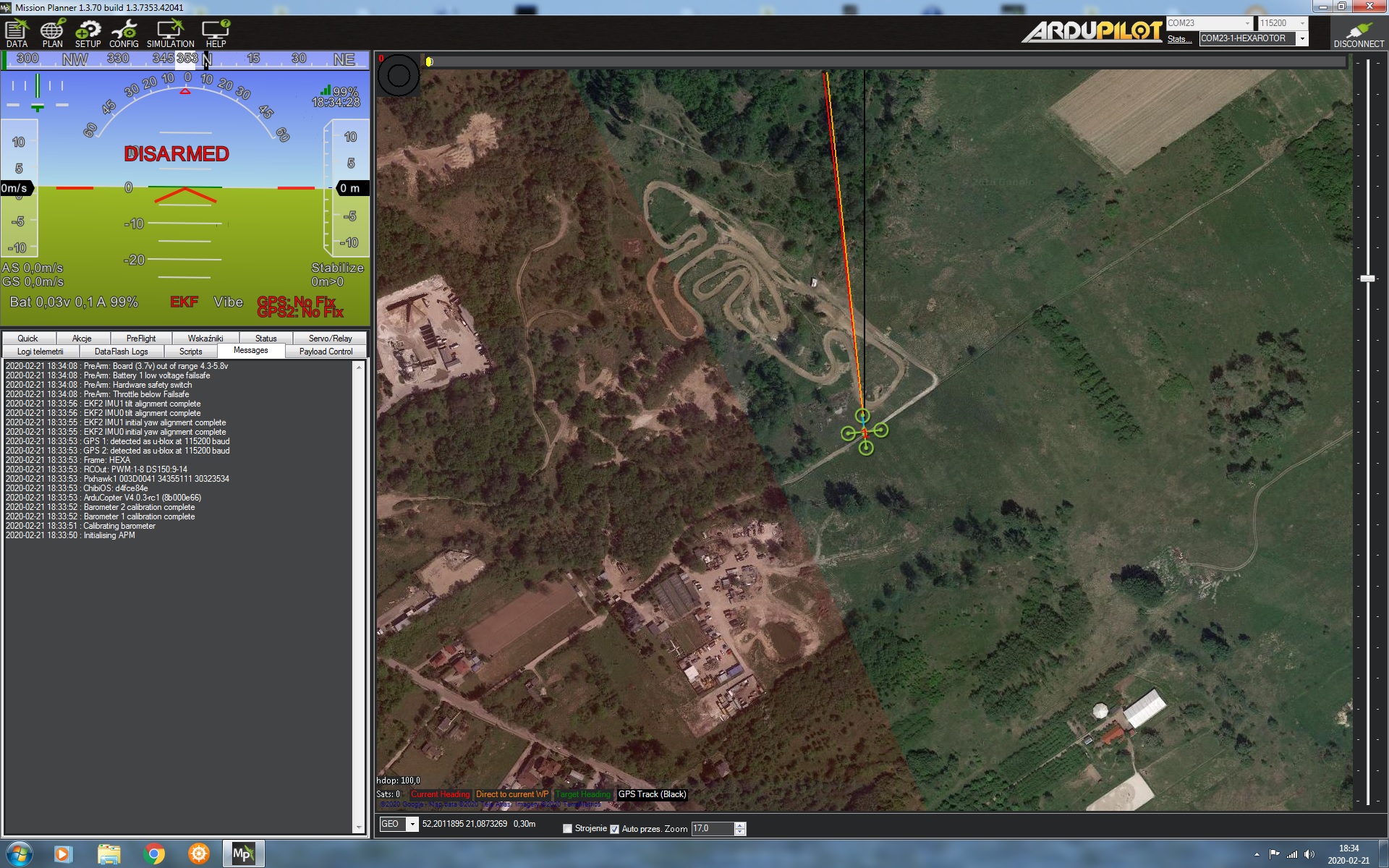
I was very happy that finally it will be known what protocol in engine control is used. I downloaded version 4.0.3-rc 1. I have HGLRC blhelis regulators. When I set the protocol to oneshot 125 or Dshot 125 (theoretically unsupported from arducopter to blhelis) I get screenshots as in the attachment. The model is hexa, regardless of whether it connects after turning on the arducopter and pressing the arming button, the image is the same. How do we know what protocol is currently going on?
Thanks for testing the “RCOut” display feature. So in the top image it shows PWM:1-8 OS125:9-14 and this is a Pixhawk1 (the board is displayed one line lower) so MAIN_OUTs 1 to 8 are outputting regular PWM values and the AUX OUTs 1 to 6 are outputting OneShot 125.
In the second image it shows PWM:1-8 DS150:9-14 so main outputs are outputting PWM, the aux outputs are outputting DShot 150.
Hi Randy,
Not sure if this is still present in this RC, but the previous RC I’m flying with many Leonard/Bill changes around feedforward has an interesting annoyance where the PreArm Mavlink message for the critical battery voltage and capacity fire after I land and disarm. Now, they’re technically accurate, but they’re coming in through the frsky passthru and causing Yaapu to constantly make the warning tone. I don’t think these should be coming across unless I try to arm, mainly because the messages are prefaced with “PreArm: “
Was that a conscious decision to fire these messages any time the voltage is low and state is disarmed, or can we send them only when trying to arm?
These appear because Copter runs the prearm checks periodically. Plane
may move the same way.
We could find some way to filter them from coming across links other than
mavlink - but these PreArm messages are really, really useful coming
across a full telemetry link.
Perhaps whatever is running on the transmitter could not sound the alarms
if it also detects the vehicle is disarmed?
That’s a question for Alex. It sounds like the decision then was a conscious one. I can get behind that, but honestly would like them to not be prefaced with “Prearm” since I’m not trying to arm. I don’t know, maybe Alex has a better idea as well.
Honestly, I don’t like them coming across on the computer either (unless I’m trying to arm), but I think I understand your rationale.
Checking the protocols, I discovered that my blhelis (no blheli32) regulators are supported in dshot 150,300,600 and work correctly with ac4.0.3-rc1. So far, I thought only blheli32 would work with ac as the wiki suggests …
This is interesting. I tried this with some BLHeli_S ESC’s configured for Dshot150 (normally run on OS125) and they work in Motor Test. The message says Dshot150 also but I’m wondering if they get a Dshot signal they don’t recognize if it reverts to PWM. So, is the message generated simply from the configured parameter or is it more sophisticated? BLHeli passthrough still doesn’t work. At least not with these ESC’s.
Edit-Nevermind, they may run in Motor Test but they stutter and don’t run properly as always when armed and running. So, with these BLHeli_S ESC’s I see no difference.
In the coming days I will check the dshot 150 thoroughly in the long flight on ESC HGLRC35A 2-5 s (so far a short test flight in the building 2min-ok) Meanwhile, the protocol switched to dshot 1200 does not cause engine rotation on these regulators (BLHeliS do not support dshot1200) so I know that it does not switch to PWM … in my spare time I will connect the osyloscope and check if there is a dshot on my blheliS for sure. But it looks like dshot support is there, and transit to the blhelis configurator is not.