
Hello everyone! I am Chenghao Tan, an undergraduate student at Hangzhou Dianzi University in China. This summer, I worked on using Luxonis AI camera for boat obstacle avoidance. First of all, many thanks to my mentors @rmackay9 and @rishabsingh3003 for providing great support to my project. Their invaluable guidance has not only benefited the progress of my GSoC project but also helped me improve my programming ideas. I would also like to thank the ArduPilot community for funding and CubePilot for providing hardware for my project. I have enjoyed an extremely delightful GSoC experience, and I will summarize my project below.
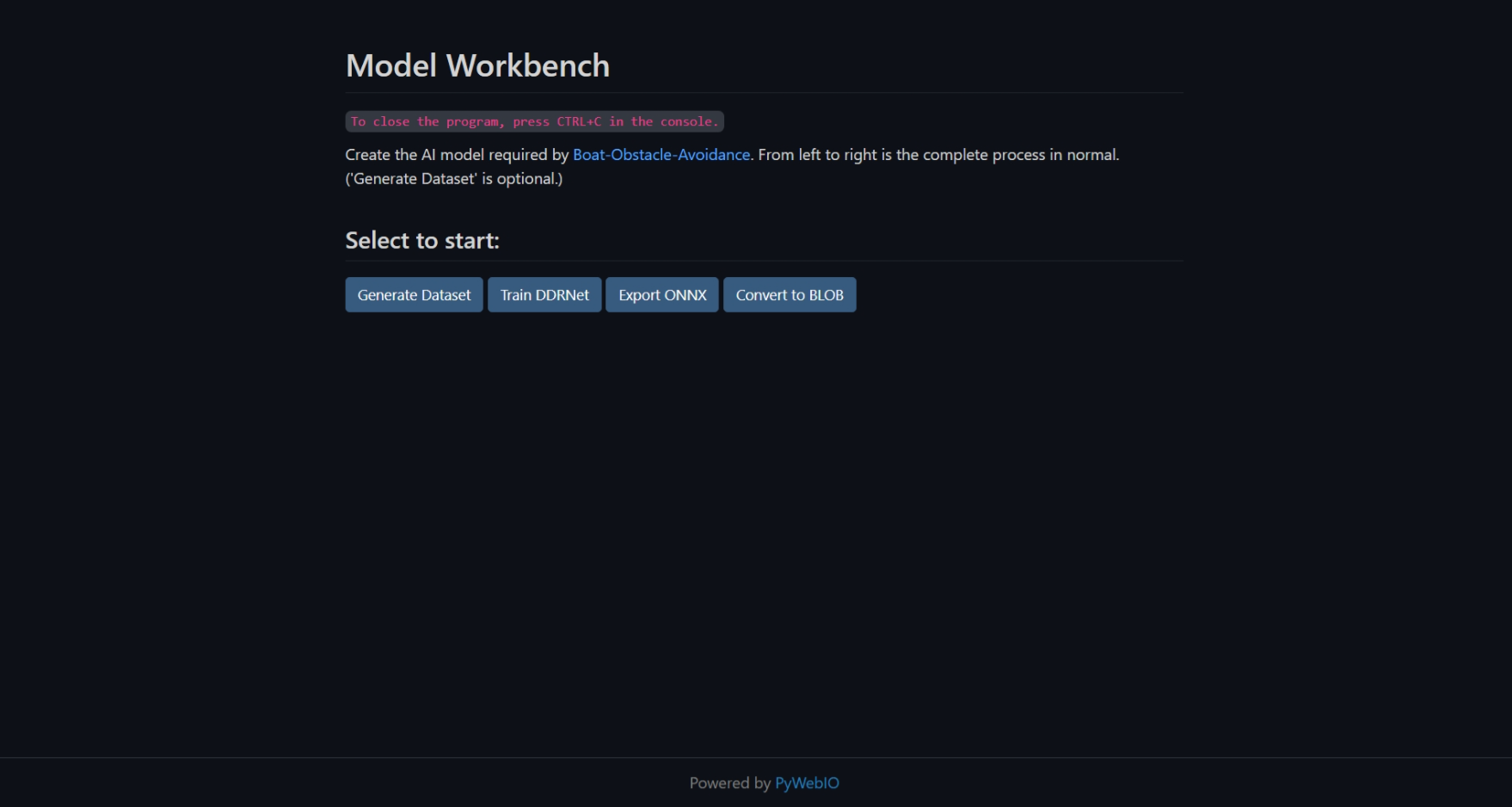
Project Description
This project involves training and integrating a Luxonis AI camera to recognize obstacles and then send their estimated position to ArduPilot’s existing object avoidance feature so that the vehicle can stop and path plan around them.
Why Luxonis
Luxonis AI camera has a built-in intel MyriadX VPU, which can run simple deep learning models and can share the computational load of the obstacle detection process.
Core Idea
The depth map obtained by the binocular camera includes the water surface. So to detect obstacles, the water surface must be removed from the depth map. However, the water surface is uneven and has a slope as the boat bumps, which makes it difficult to be separated from the obstacles. Since the Luxonis AI camera itself has relatively powerful computational ability and comes with an RGB camera, we can perform the removal of water surface with the help of deep learning.
One option is to use the object detection model to mark out the obstacles directly. The problem with this is that there are too many kinds of obstacles for the dataset to cover.
The scheme used in this project is to use an image segmentation model to filter the water surface pixel by pixel on the depth map and then do subsequent processing on the depth map with only obstacle pixels left.
Dataset Selection
I found an excellent dataset, MaSTr1325. It has masks of water, obstacles, and sky, with a total of 1325 images. I reclassified the pixels into obstacle and non-obstacle categories during training—filtering out the water and sky, leaving the obstacles. Since there are distracting factors such as rain, snow, sun flare, and shadows in reality, and this dataset is too “clean”, the data was augmented using the albumentations library, adding random color jitter and geometric distortions along with the above factors. Nevertheless, more data is better. The training framework has been simplified, and the link is attached at the end of the blog, so feel free to add your own data to train a better model!
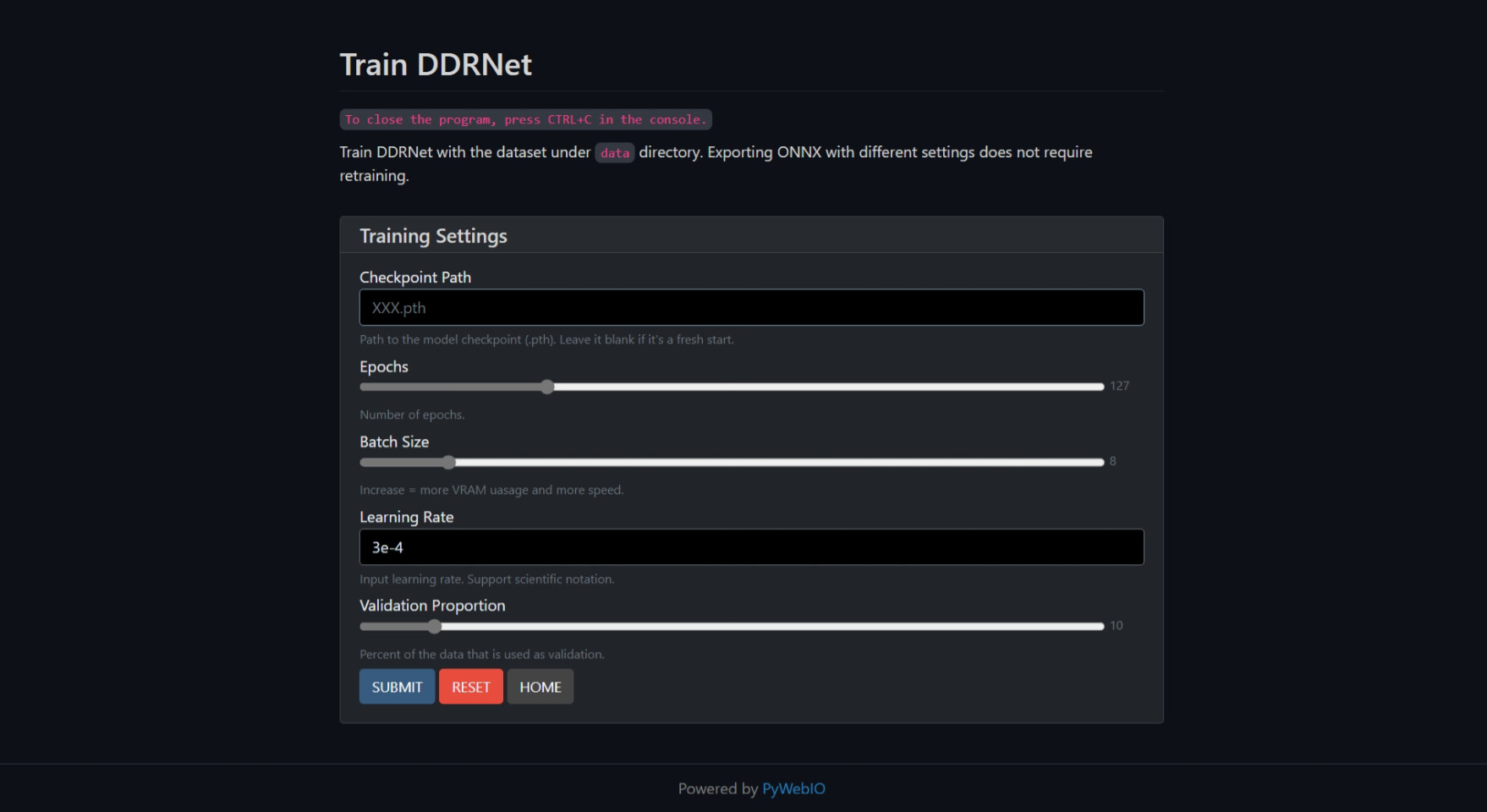
Model Training
I first tried UNet, which is widely used in image segmentation tasks. Although it performs well during validation, it is too heavy for the Luxonis AI camera. Even after pruning, it only reaches eight frames per second at 480*270, so it has now been replaced. (But you can still see it in the test script repository and the training framework support.) I ended up using DDRNet. When doing a pure segmentation job, it reached up to 28 frames per second at 640*360 with no noticeable latency. DDRNet running on Luxonis AI camera can reach up to 0.75 mIoU testing with XLink.
Segmentation Demo



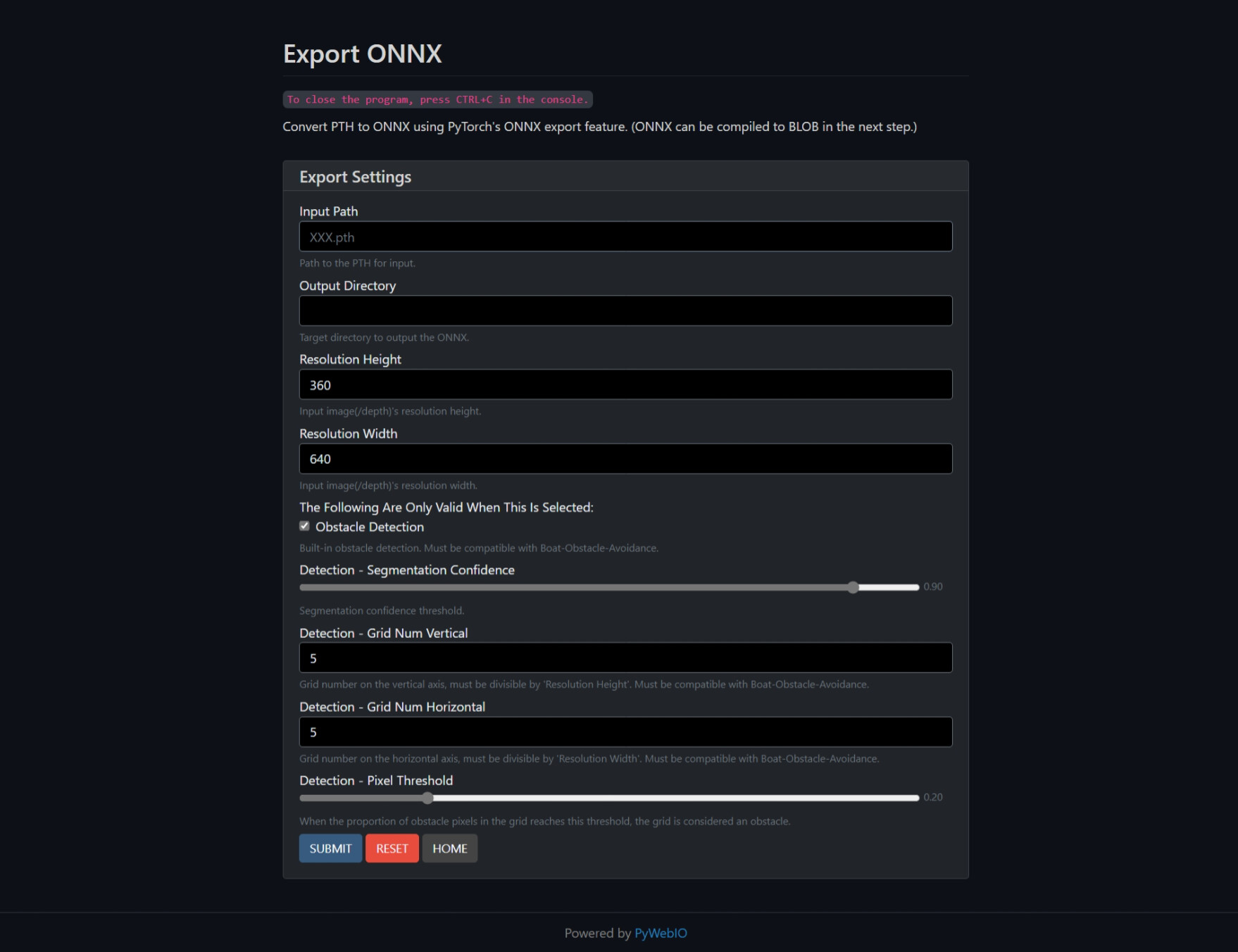
Obstacle Location Acquisition
The filtered depth map is divided into grids. Grids with obstacle pixels that exceed a threshold will be marked. Large obstacles will cover multiple grids to let ArduPilot know their actual size. This processing part is implemented manually and embedded into the model’s tail due to speed consideration and DepthAI’s limitation.
The real-world obstacle coordinates are computed in two alternative ways. One follows the Luxonis’ official host-side demo, using only HFOV; the other refers to the point cloud calculation method proposed in the Luxonis community, using the camera’s intrinsic matrix. This part runs on the companion computer and will automatically read the calibration information from the camera when it starts.
Sending Obstacle Location Messages
This part differs from the original proposal in that the planned OAK-D-IoT series is no longer available, so a companion computer such as Raspberry Pi is used instead (the branch that sends messages using onboard ESP32 is still retained but buggy). Since Luxonis AI camera is responsible for most of the computation, the performance of the companion computer does not need to be very high, and a Raspberry Pi zero should be able to handle this task.
Unless the frame is not ready, the companion computer will send obstacle_distance_3d messages at a constant rate. If there are no obstacles on the entire frame, a message with a distance of maximum effective distance+1 will be sent. If the camera fails, then no obstacle location message will be sent.
What’s Next
-
Both passive depth estimation and RGB camera require sufficient light. The former can be alleviated by projecting IR dots (some new Luxonis AI cameras have this feature), but the latter is trickier, and even with supplemental visible light, we need the appropriate dataset.
-
Reflections and multi-scale objects have always been difficult for image segmentation tasks, especially for those small models. The model used now sometimes has difficulty distinguishing between reflections and real obstacles. It’s also known that when boats or obstacles are in the area covered by trees’ or coasts’ reflections, there’s a significant drop in segmentation accuracy. Massive objects covering the entire image’s upper half also have this effect. Limited by the computing resource of the camera, the best way at present might be to augment the dataset, making up for these lacks in MaSTr1325.
-
When using the software implementation to detect obstacles, the workload is too heavy for companion computers such as Raspberry Pi and is only suitable for tuning parameters. However, the hardware implementation has parameters such as confidence threshold fixed. Therefore, precompiled blob file with different parameters will be provided soon.
Repositories
-
Boat obstacle avoidance: GitHub - Chenghao-Tan/Boat-Obstacle-Avoidance: Boat Object Avoidance with Luxonis AI Camera Using Image Segmentation
Running on the companion computer.
-
DDRNet training framework: GitHub - Chenghao-Tan/DDRNet: DDRNet for marine segmentation.
To add custom model support, simply import the classes in models/extra.py to add pre-processing and post-processing procedures.
-
Visualization tests and useful widgets: https://github.com/Chenghao-Tan/Depthai-Demo-Script
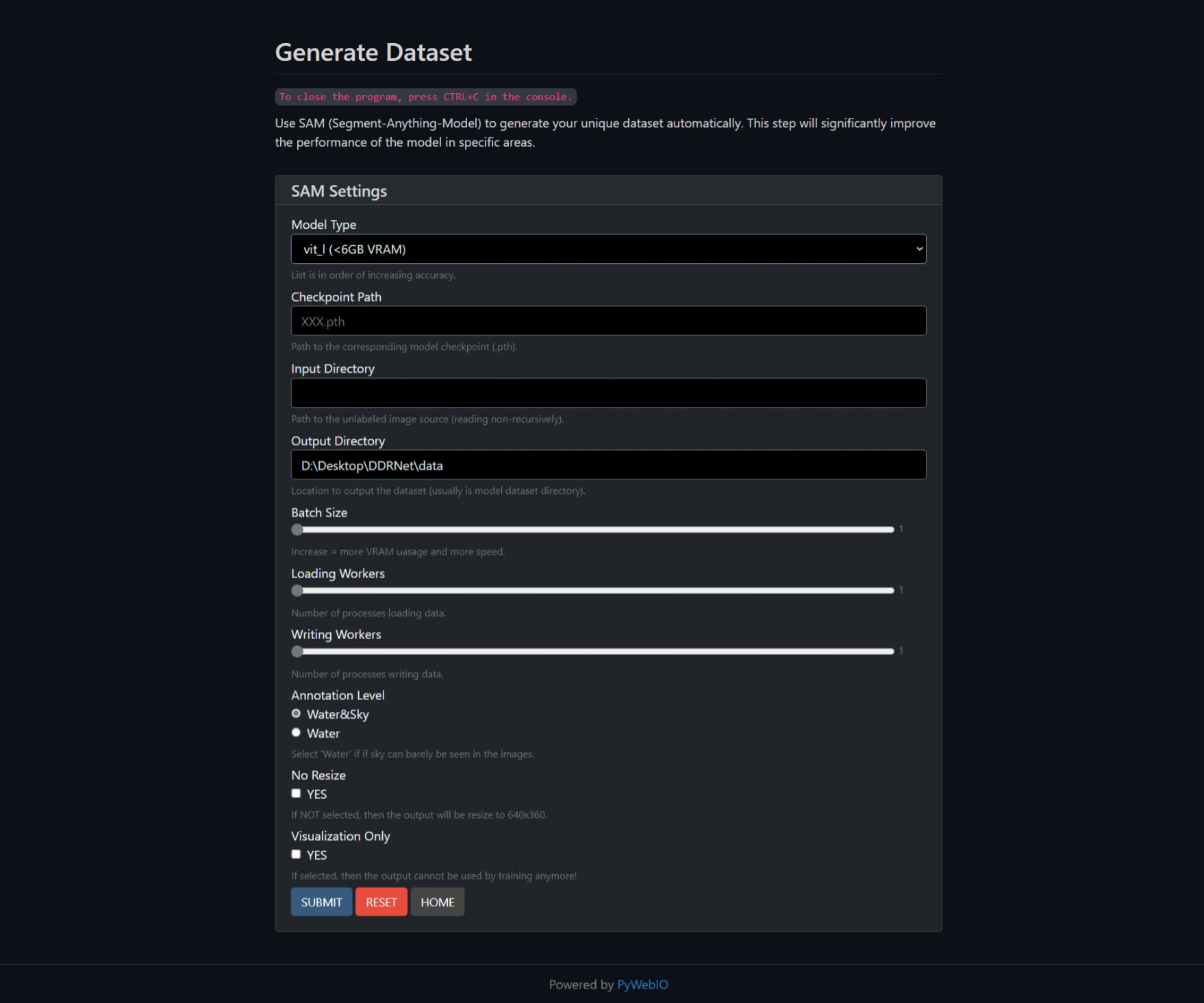
 Using Segment Anything Model in a Real-World Scenario")
 and Retraining")